File Processing
Make documents read and structure themselves, so manual data entry disappears.
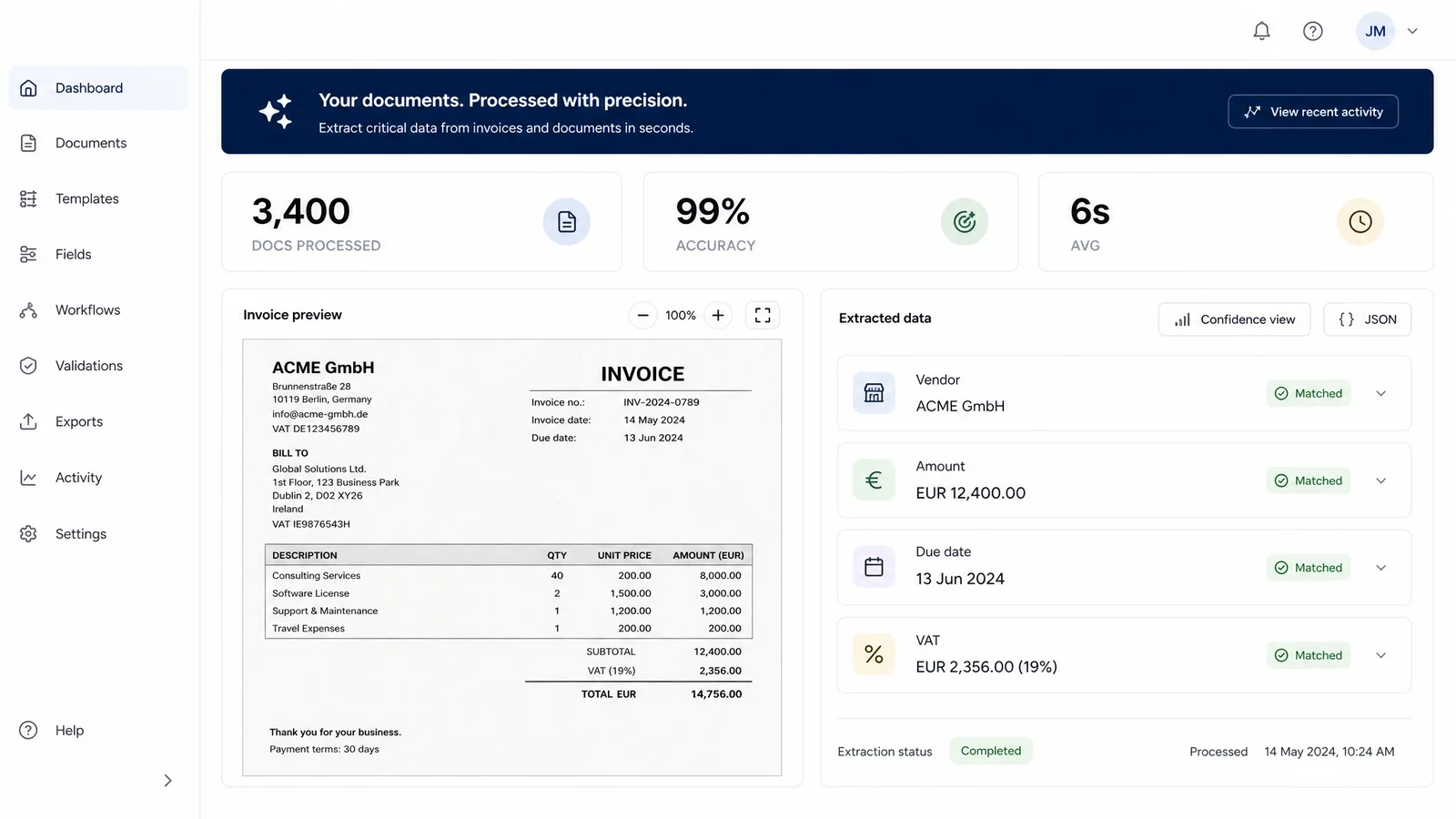
Invoices, contracts, receipts, forms: most of them still get typed into a system by hand. We build pipelines that read documents automatically, pull out the fields that matter, structure them, and hand you clean data ready to use.
This works on scanned and photographed files too, through OCR, which means reading text out of an image. The system validates what it extracts, flags anything that looks off, and delivers the result as a table, an Excel or CSV file, or straight into your system.
What it does
OCR
Read text out of scans, photos and PDFs, so even a phone snapshot of a receipt becomes machine readable data.
Extraction
Pull the fields that matter, amount, date, supplier, line items, automatically from each document, no matter its layout.
Structuring
Turn loose document content into clean, consistent records ready for your database, accounting or spreadsheet.
PDF to Excel or CSV
Convert stacks of PDFs into structured tables, so a pile of files becomes a usable dataset in one pass.
Validation
The system checks extracted data against rules and expected formats, and flags anything that looks wrong for a quick human review.
Classification and filing
Documents are recognised and sorted into the right category and folder automatically, so nothing gets lost or misfiled.
Finance receives 500 supplier invoices in a month. Instead of typing each one in, the pipeline reads every file, extracts amount, date and supplier, validates the totals, flags two that do not add up, and drops the rest into a clean table ready for the accounting system.
What you get
- Documents read and structured automatically
- Manual data entry disappears
- Data ready to use instantly, in your format
- Works on scans and phone photos, not just clean PDFs
- Errors caught early through automatic validation
Questions
Does it work on scanned or photographed documents?
What if a document is misread?
Can it handle different invoice layouts?
Stop typing what a machine can read
Book a call and we will show how your documents could structure themselves.